Four balanced metrics
Measure what matters. Let the team own it.
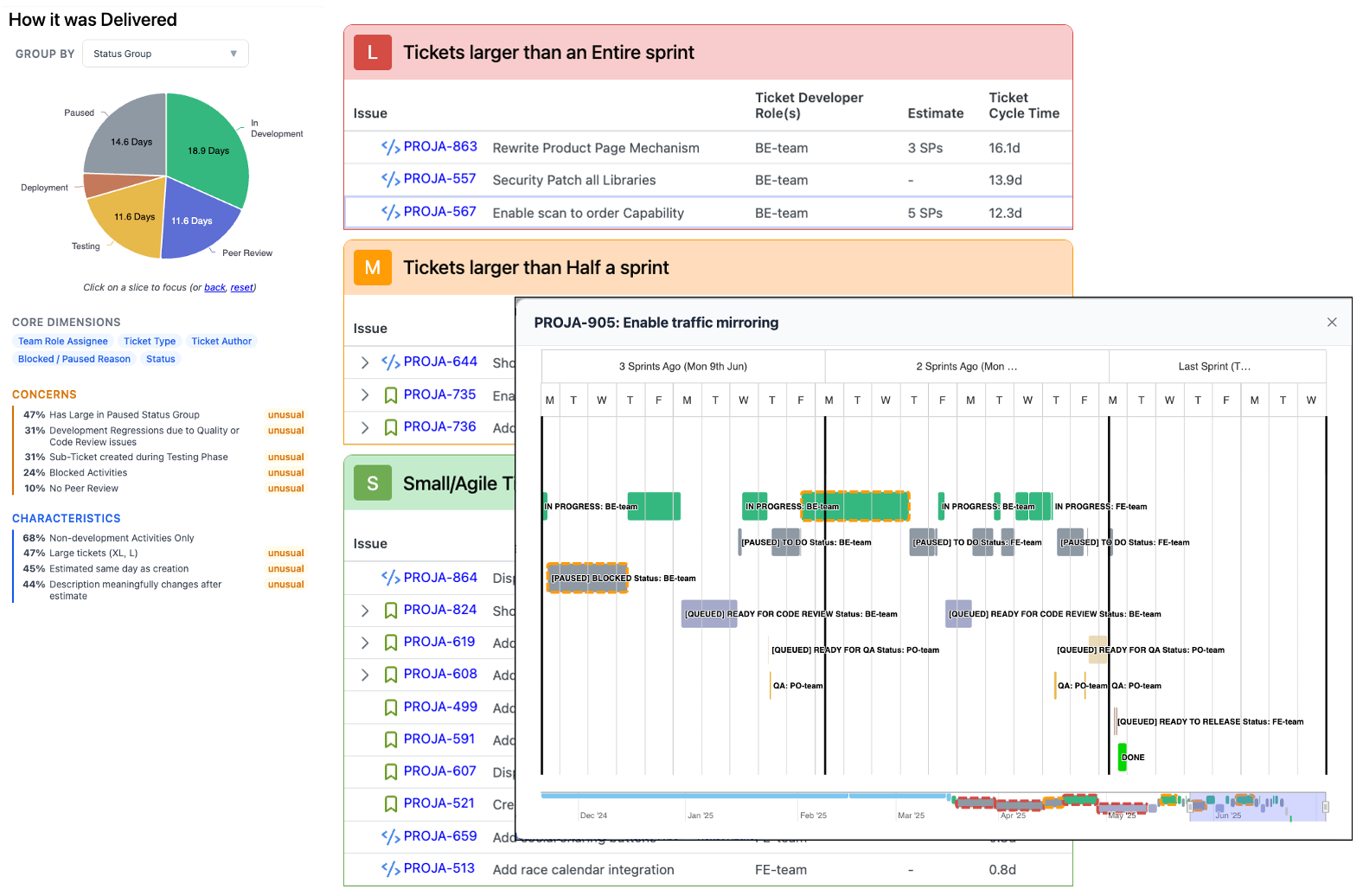
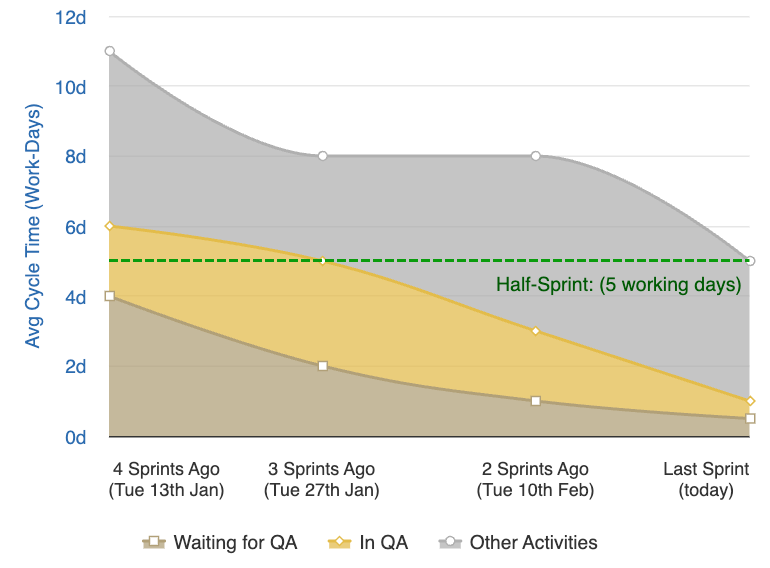
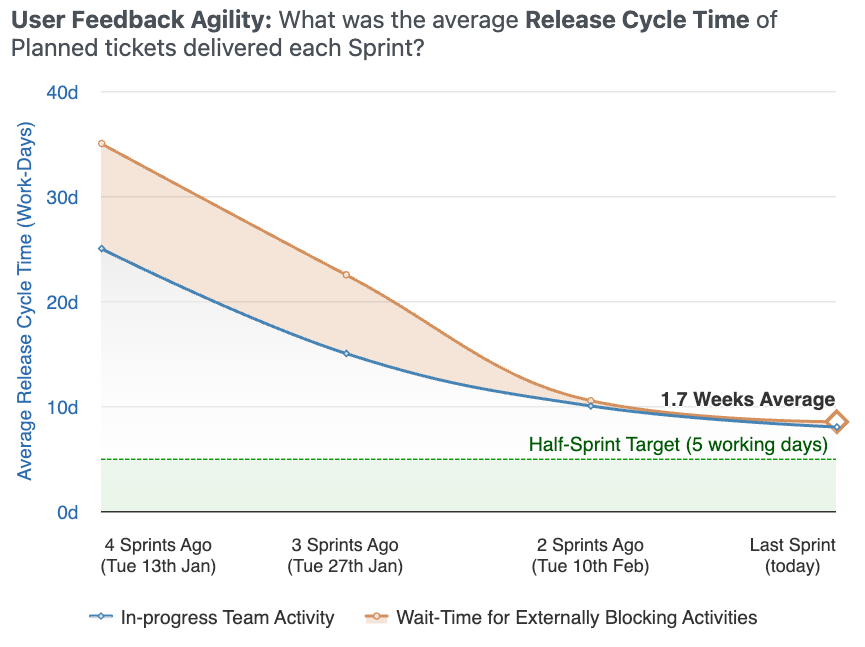
Release Cycle Time
Planned work shouldn't take more than half a sprint.
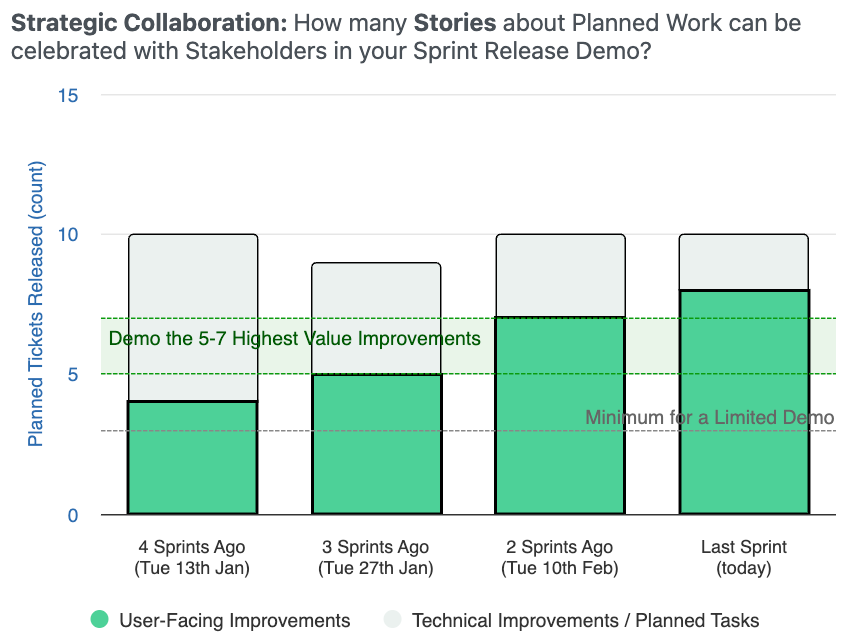
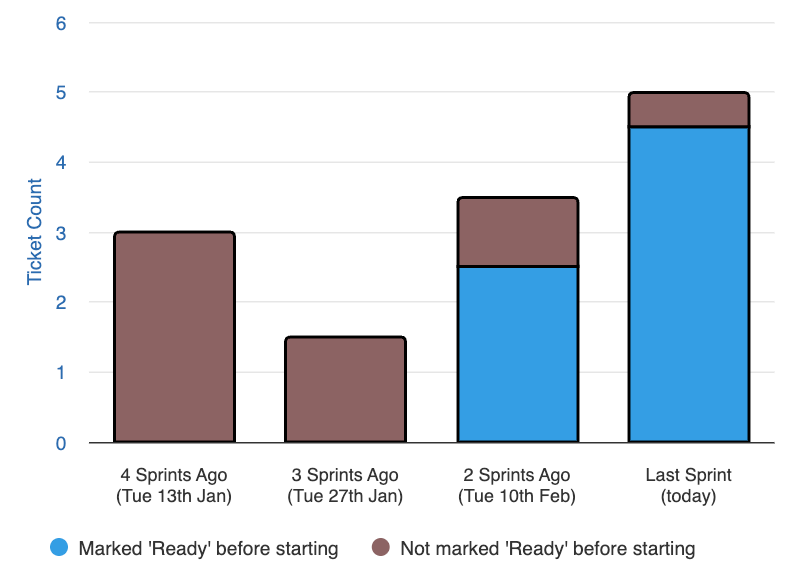
Tickets Released
Small, frequent releases are the foundation.
Defect Rate
Speed without quality creates more work, not less.
Defect Recovery Time
When something breaks, how fast does the team recover?
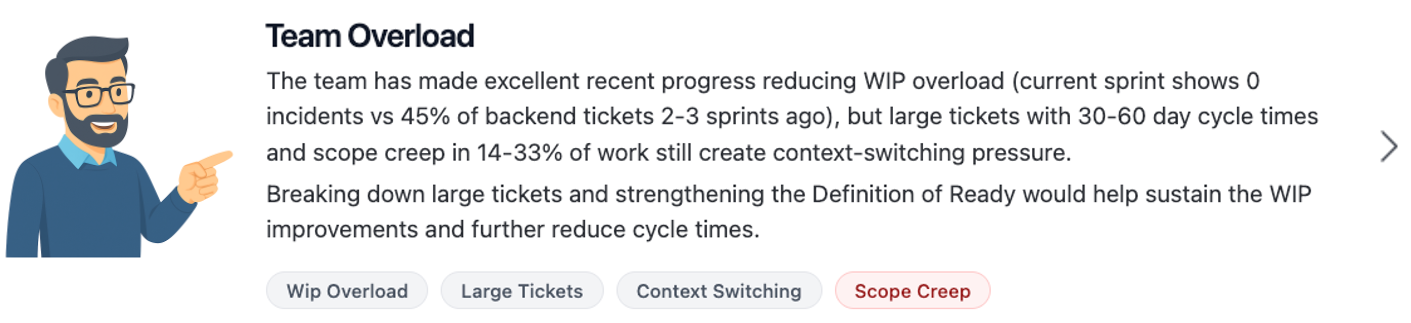
These four metrics balance each other. Optimising one at the expense of another always shows up. The only way through is to genuinely improve.
Recadence additionally monitors structural health indicators for engineering leaders: WIP creep, external blockers, reactive distractions, defect backlog build-up, unfinished carry-over, cancelled work. Signals to offer support, not surveillance.